Sampling and Interpolation with QGIS
Turn-in for grading: This lab includes material that must be turned in for grading. Complete the required deliverables and submit them as instructed by the course.
Overview
This lab introduces sampling strategies and spatial interpolation methods in QGIS. Instead of using raster data as-is, you will create new raster surfaces from point samples using three different interpolation techniques.
You will work with a digital elevation model (DEM) of southeast Arizona to:
- create sample point layers using systematic, random, and stratified sampling strategies
- extract elevation values at those sample points
- interpolate new raster surfaces from the samples using Inverse Distance Weighting (IDW), Nearest Neighbor, and Radial Basis Function (RBF) methods
- compare the interpolated surfaces to the original DEM to understand the strengths and limitations of each method
Concept note: Sampling and interpolation are fundamental to converting sparse point measurements (like weather stations or survey points) into continuous raster surfaces that cover an entire area. The method you choose affects how smooth the output is, how well it honors the original sample values, and how it represents areas between samples.
What You Should Understand After This Lab
By the end of this exercise, you should be able to explain:
- the difference between systematic, random, and stratified sampling strategies and when to use each
- how interpolation methods like IDW, Nearest Neighbor, and RBF create raster surfaces from point data
- why stratification can be useful when sampling density matters in some regions more than others
- how filtering operations like majority filtering generalize raster data
- how to compare interpolated surfaces to original data to assess interpolation quality
Getting Ready
You will need:
- ChirDEM.tif, a GeoTIFF containing the elevation data for this exercise
- QGIS with Processing Toolbox and GDAL tools available
- SAGA tools for SAGA-based processing steps. SAGA must be installed separately and configured through the QGIS Processing Saga NextGen Provider plugin. If you have not set this up yet, complete the Week 00 guide for Installing SAGA 9.2 for QGIS Processing.
Background: The concepts and workflows in this exercise are covered in Chapter 12 (Spatial Estimation) and Chapter 10 (Raster Analysis) of the GIS Fundamentals textbook.
Download the Data
This file is a GeoTIFF containing the digital elevation model for southeast Arizona (30-meter resolution, NAD83 UTM Zone 12N projection).
Project Setup
- Create a new folder for this lab on your computer.
- Place
ChirDEM.tifin that folder. - Create a new QGIS project in that same folder and save it as
sampling_interpolation.qgz. - You will create all output layers (sample points, interpolated rasters, etc.) in this project folder.
Data for This Exercise
The main data layer is:
ChirDEM.tif: A digital elevation model of southeast Arizona at 30-meter resolution, in NAD83 UTM Zone 12N projection (EPSG:26912)
You will create multiple output layers in this lab, including sample point layers, interpolated raster surfaces, and a stratification layer based on slope classification.
Part 1: Preparing the DEM and Creating a Base Hillshade
We’ll start by adding the DEM and creating visualization layers to help us understand the terrain variation.
- Start QGIS, add the DEM from southeast Arizona, ChirDEM, and apply a color scheme to highlight topography in the DEM. Note the variation in topography—where there is significant change and where there is little change.
- Open Processing > Toolbox and search for Hillshade.
- Use Raster > Terrain Analysis > Hillshade to create a hillshade with:
- Solar altitude (vertical angle):
25 degrees - Azimuth:
315
- Solar altitude (vertical angle):
- Browse and name the output:
Hillshade
- When finished, place the
Hillshadeunderneath theChirDEMin the layers panel. - Set the
ChirDEMRendering to Multiply in the Layer Styling panel to blend the hillshade with the elevation colors.
Workflow note: Hillshades help visualize terrain detail by showing the interplay of light and shadow. Placing the DEM above a hillshade using Multiply blending combines color information with shading for a richer visualization.
Organizing Your Layers into Groups
To keep your work organized as you create multiple interpolation outputs, you will group related layers in the Layers panel. This lab will involve four different interpolation approaches, each with a related set of data layers.
- Select both the DEM and hillshade in the Layers panel (shift-click on PC, cmd-click on Mac), then right-click and select “Group Selected” from the dropdown.
- Rename this group:
Original
As you create layers for each interpolation method, select appropriate layers and group them with logical names. Suggested group names:
OriginalInverse DistanceNearest NeighborRBF Stratified
If a layer ends up in the wrong group, right-click and select Move Out of Group.
Workflow note: Organizing your layers into groups from the start makes it easier to manage the many intermediate outputs you will create and to prepare your final map layout.
Final Output Layout: Your maps will be arranged in a landscape orientation with four side-by-side map frames, one for each interpolation method. Each frame should display the interpolated surface, its hillshade, and contours, arranged consistently across all four maps.

Part 2: Systematic Sampling and IDW Interpolation
In this part, you will create a regular grid of sample points evenly spaced across the DEM, extract elevation values at those points, and then use Inverse Distance Weighting (IDW) interpolation to create a continuous raster surface from those samples.
Concept note: Systematic sampling creates an evenly spaced grid of sample points, which is useful for uniform coverage and is easy to implement. However, it can miss important variation if spatial features align poorly with the grid direction.
Creating a Regular Grid of Sample Points
- Open Vector > Research Tools > Regular Points (or search for Regular Points in the Processing Toolbox).
- Set the input extent by clicking the options button and selecting Calculate from layer, using the
ChirDEMlayer. - Set the point spacing/count to
1000meters. - Check Use point spacing to specify that you want points 1000 meters apart.
- Specify an output coordinate system if it is not already set to
EPSG:26912(the CRS ofChirDEM). - Browse and save the output as SystematicGrid1000m.shp.
A regular grid of points should be displayed on your screen. If not, navigate to the file you created and add it to the project.
Concept note: A 1000-meter spacing creates approximately 1000 sample points across the study area, providing uniform coverage without specifying a point count directly. This regular spacing ensures unbiased sampling across all terrain types.
Extracting Elevation Values at Sample Points
Next, you will sample the elevation values from the DEM at each grid point location.
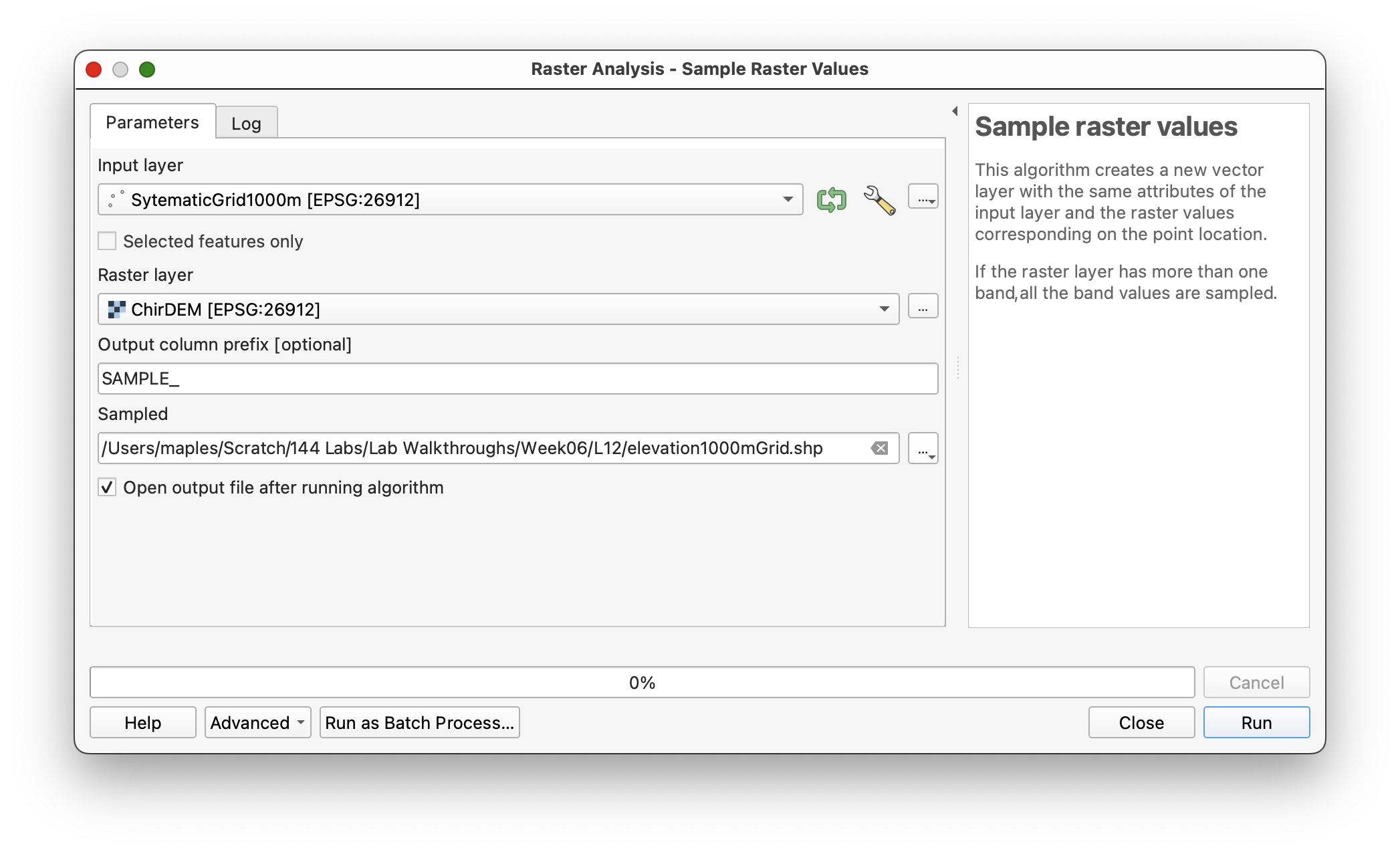
This generates a point layer with an added attribute column containing the sampled elevation value below each point:
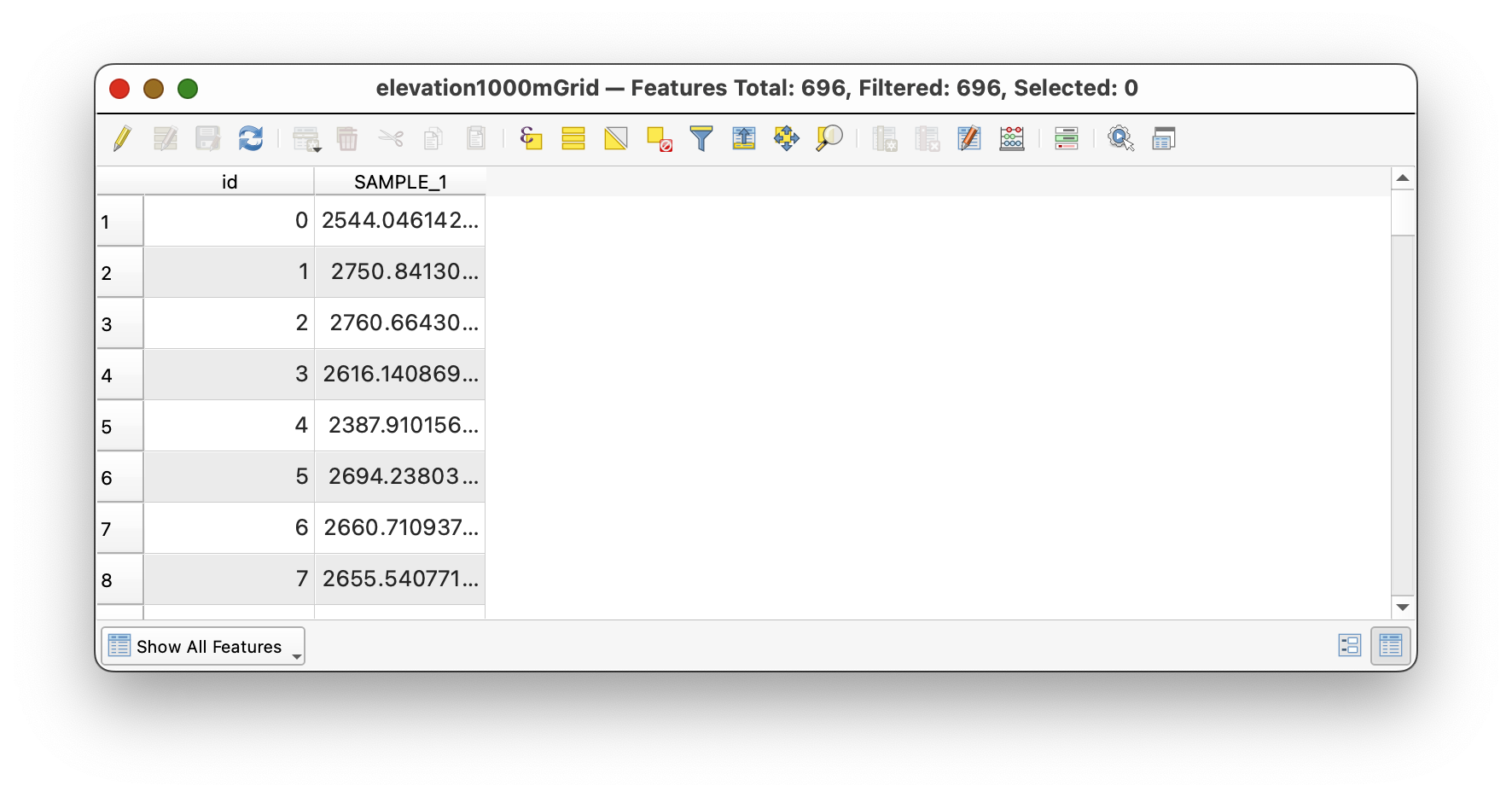
Open the attribute table and inspect the SAMPLE_1 column, which now contains elevation values extracted from the DEM.
Workflow note: The column prefix (
SAMPLE_) is prepended to the raster band number to create column names. SinceChirDEMhas one band, the result isSAMPLE_1.
Interpolating a Surface with Inverse Distance Weighting (IDW)
Now you will create a new raster surface by interpolating from these sample points using IDW, which weights nearby points more heavily than distant ones.
- Return to the Processing Toolbox and search for GRID: Inverse distance to a Power.
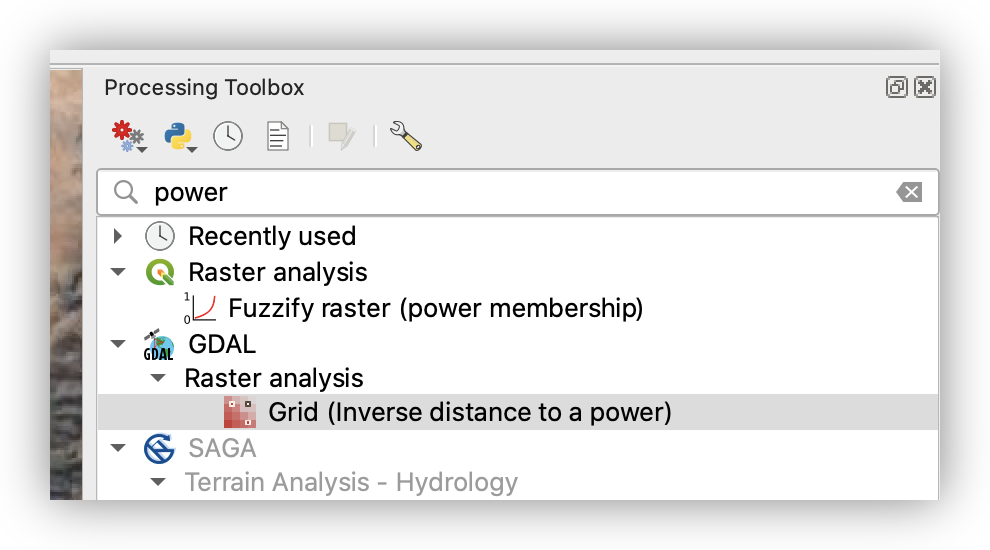
- Specify:
- Point layer:
Elevation1000mGrid - Weighting power:
2 - Smoothing:
1 - Search ellipse radii (X and Y):
1000meters for both - Maximum number of data points to use:
12 - Minimum number of data points to use:
1
- Point layer:
- Open Advanced Parameters and set:
- For the output raster cell size, paste this into Additional command-line parameters [optional]:
-tye 3498779.8925000000745058 3522569.8972999998368323 -txe 658307.9677000000374392 686597.9734000000171363 -outsize 943 793
These parameters specify the output extent and dimensions (943 × 793 pixels) to match the original DEM’s 30-meter cell size. See the GDAL Grid documentation for more details.
- Browse and name the Interpolated (IDW) Output:
IDWsysP2_12 - Run the tool.
Concept note: IDW interpolation calculates each output cell value as a weighted average of nearby sample points. The weighting power (2 in this case) controls how much closer points are favored—higher values make distant points matter even less. The search radius limits which points contribute to each cell, creating the characteristic “pattern” you see where nearby sample points create local influence zones.
The resulting map shows clear pattern marks where sample points and search ellipses interact:
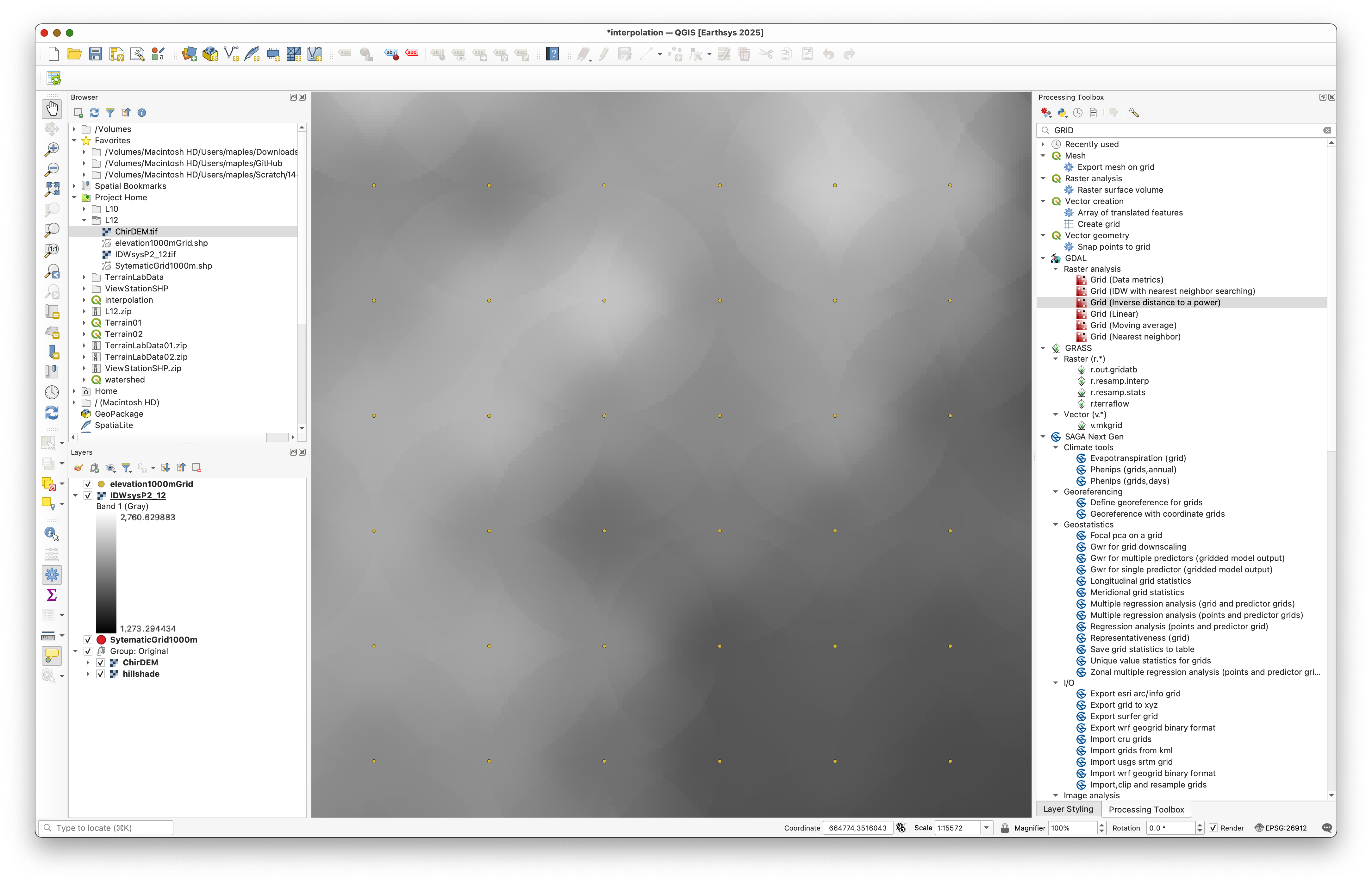
Styling the IDW Surface
Now apply the same color scheme used for the original DEM to the interpolated surface so they are visually comparable.
- Return to your Original group and right-click on the
ChirDEMlayer. - Select Styles > Copy Style.
- Right-click on your
IDWsysP2_12layer and select Styles > Paste Style to apply the same color ramp and classification.

Creating Contours from the Interpolated Surface
Contours help visualize the shape of the interpolated surface and make it easier to compare across methods.
- Open Main Menu > Raster > Extraction > Contour.
- Specify:
- Input layer:
IDWsysP2_12 - Interval:
100(meters, matching the DEM's coordinate system units) - Contours output: Browse and save as
IDW100mContours.shp
- Input layer:

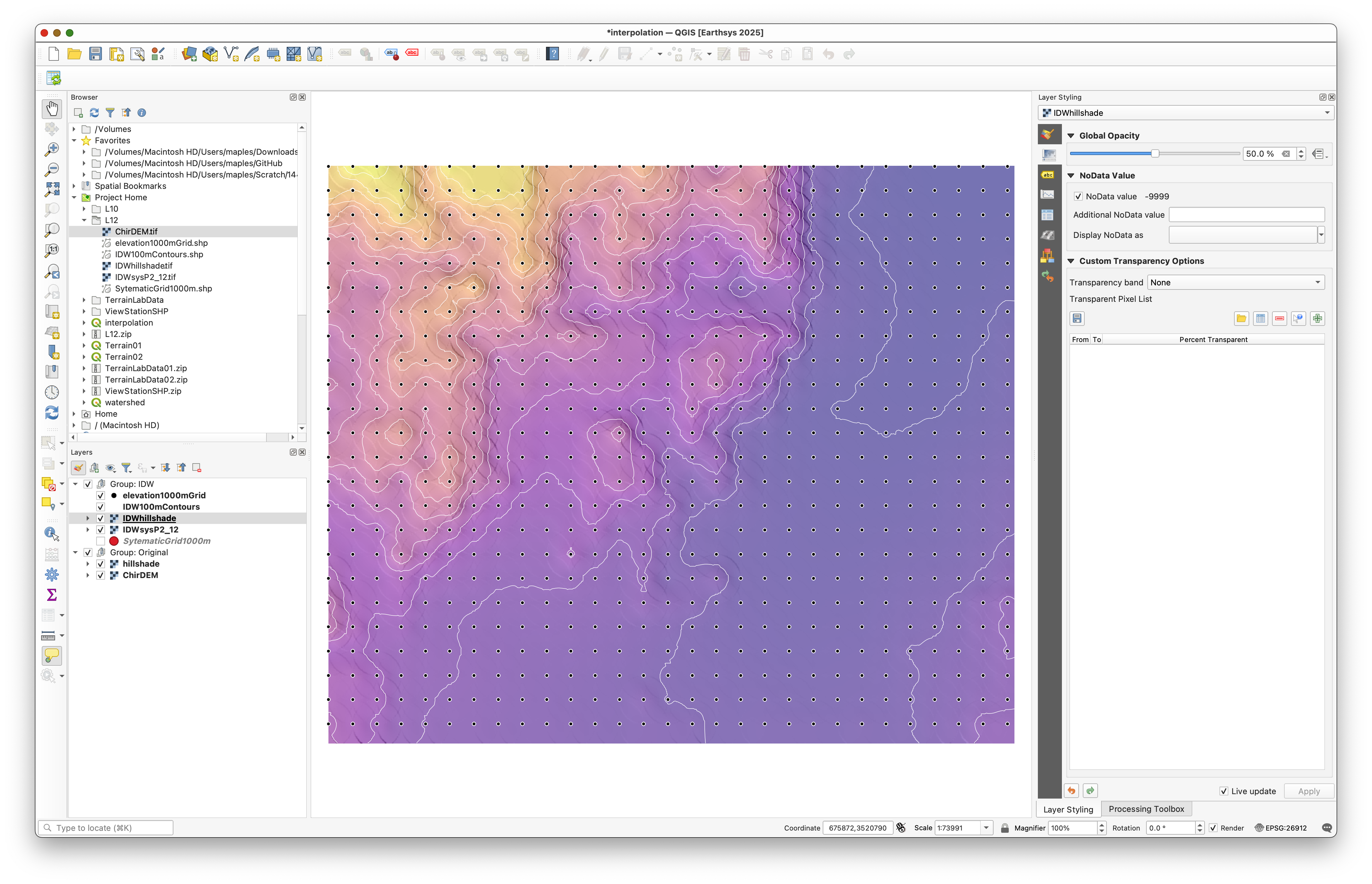
- As you did with the original DEM, use Raster > Terrain Analysis > Hillshade to create an
IDWHillshadelayer using the same parameters (Azimuth 315, Elevation 25). - Group the
IDWsysP2_12,IDWHillshade, andIDW100mContourslayers in a group namedInverse Distance. - Arrange the layers so that your hillshade is positioned between the interpolated raster and the contours, similar to the image below (colors may vary):
Part 3: Random Sampling and Nearest Neighbor Interpolation
In this part, you will create a random sample of points, extract elevation values, and use Nearest Neighbor interpolation, which produces a distinctly different result from IDW.
Concept note: Random sampling avoids the artificial grid pattern of systematic sampling and is good when you want unbiased point placement. However, random samples can accidentally cluster in some areas and leave gaps in others, which affects interpolation quality.
Creating Random Sample Points
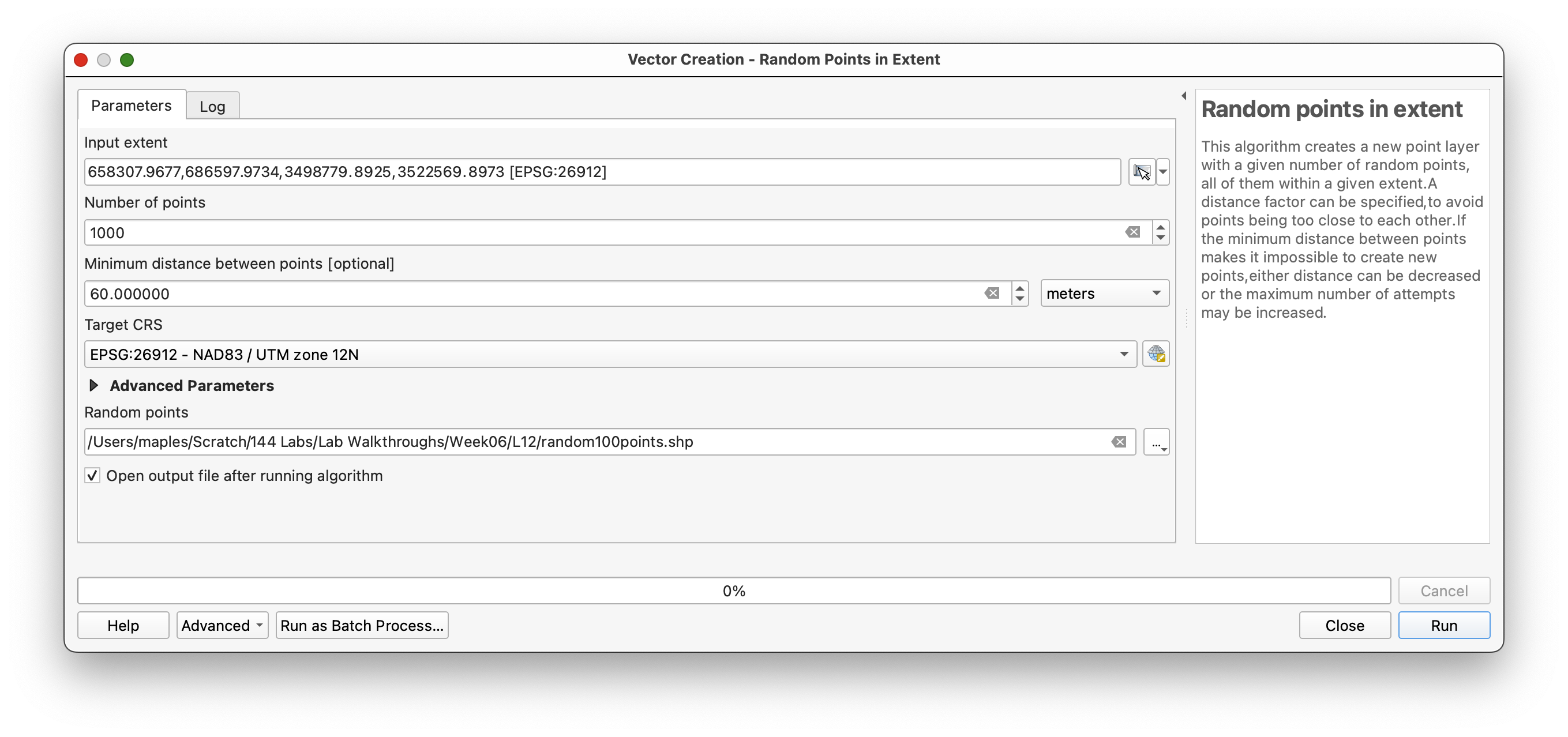
- Open Vector > Research Tools > Random Points in Extent.
- Set the Input extent by clicking ... > Calculate from Layer and selecting
ChirDEM. - Specify:
- Number of points:
1000 - Minimum distance:
60 meters(to prevent clustering) - Maximum number of search attempts:
200
- Number of points:
- Browse and save the output as Random1000Points.shp.
- Now extract elevation values from the DEM at these random points using Processing Toolbox > Raster > Analysis > Sample raster values.
- Name the output Random1000Elevation.
Workflow note: The minimum distance parameter ensures points don’t cluster too tightly, which would create redundant samples. This improves spatial coverage while still preserving randomness.
Nearest Neighbor Interpolation
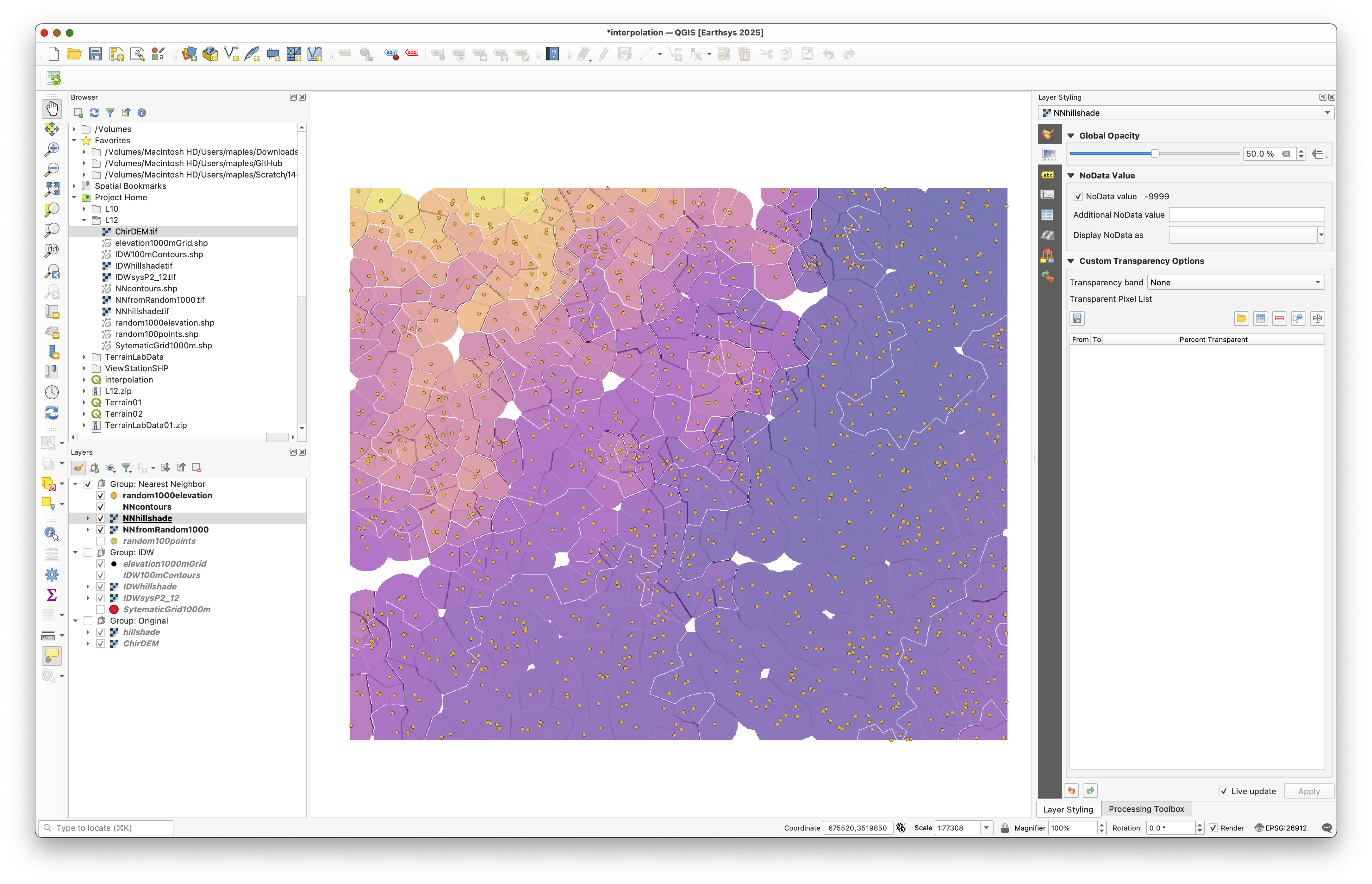
Nearest Neighbor interpolation creates a stepped surface where each raster cell takes the value of the single nearest sample point. This produces output similar to Voronoi polygons and is useful when you want to preserve original sample values without smoothing.
- Search the Processing Toolbox for Grid (Nearest Neighbor) under GDAL > Raster Analysis.
- Specify:
- Paste the same command-line parameters into Additional command-line parameters [optional]:
-tye 3498779.8925000000745058 3522569.8972999998368323 -txe 658307.9677000000374392 686597.9734000000171363 -outsize 943 793
- Browse and name the output: NNfromRandom1000.tif
- Run the tool.
Concept note: Nearest Neighbor is a deterministic method—each cell always takes the value of its nearest point. Unlike IDW, which blends values from multiple neighbors, Nearest Neighbor creates discrete zones of constant elevation, making it useful when you have authoritative point measurements that should not be smoothed or averaged.
Styling and Visualizing Nearest Neighbor Results
- Copy the style from your original
ChirDEMlayer and paste it ontoNNfromRandom1000.tif, just as you did for the IDW result. - Create contour lines from the Nearest Neighbor surface using Raster > Extraction > Contour with an interval of
100meters. - Create an
NNHillshadelayer using Raster > Terrain Analysis > Hillshade with Azimuth 315 and Elevation 25.
- Create a Nearest Neighbor group in the Layers panel containing the sample points, contours, and interpolated raster layers.
Your results should resemble the figure below. Note that since the sampling is random, your exact map will differ:
Part 4: Stratified Random Sampling and Radial Basis Function (RBF) Interpolation
Important update: The older SAGA Multi-level B-spline tool is discontinued in the QGIS/SAGA workflow used by this lab. It has been replaced here with the Whitebox Tools Radial Basis Function (RBF) Interpolation tool. Some screenshots below will still show the older spline method until they are refreshed, but the instructions and tool guidance in this section now refer to the Whitebox RBF tool.
In this part, you will implement a more sophisticated sampling strategy: stratified random sampling. Instead of sampling uniformly across the landscape, you will increase sampling density in steep areas where terrain variation is greatest. You will then use Radial Basis Function (RBF) interpolation, which creates a smooth surface with continuous curvature.
Concept note: Stratified sampling is useful when different parts of your study area have different importance or variability. By stratifying on slope, you sample more densely where terrain is complex and less densely where it is simple. This is more efficient than uniform sampling for capturing important variation.
Step 1: Calculate Slope
Begin by deriving a slope layer from the DEM. Your strata boundaries will be based on slope classes.
- Open Processing Toolbox > Raster > Analysis > Slope.
- Use
ChirDEMas the input. - Use the default settings (slope output in degrees).
- Browse and save the output as SlopeDegrees.
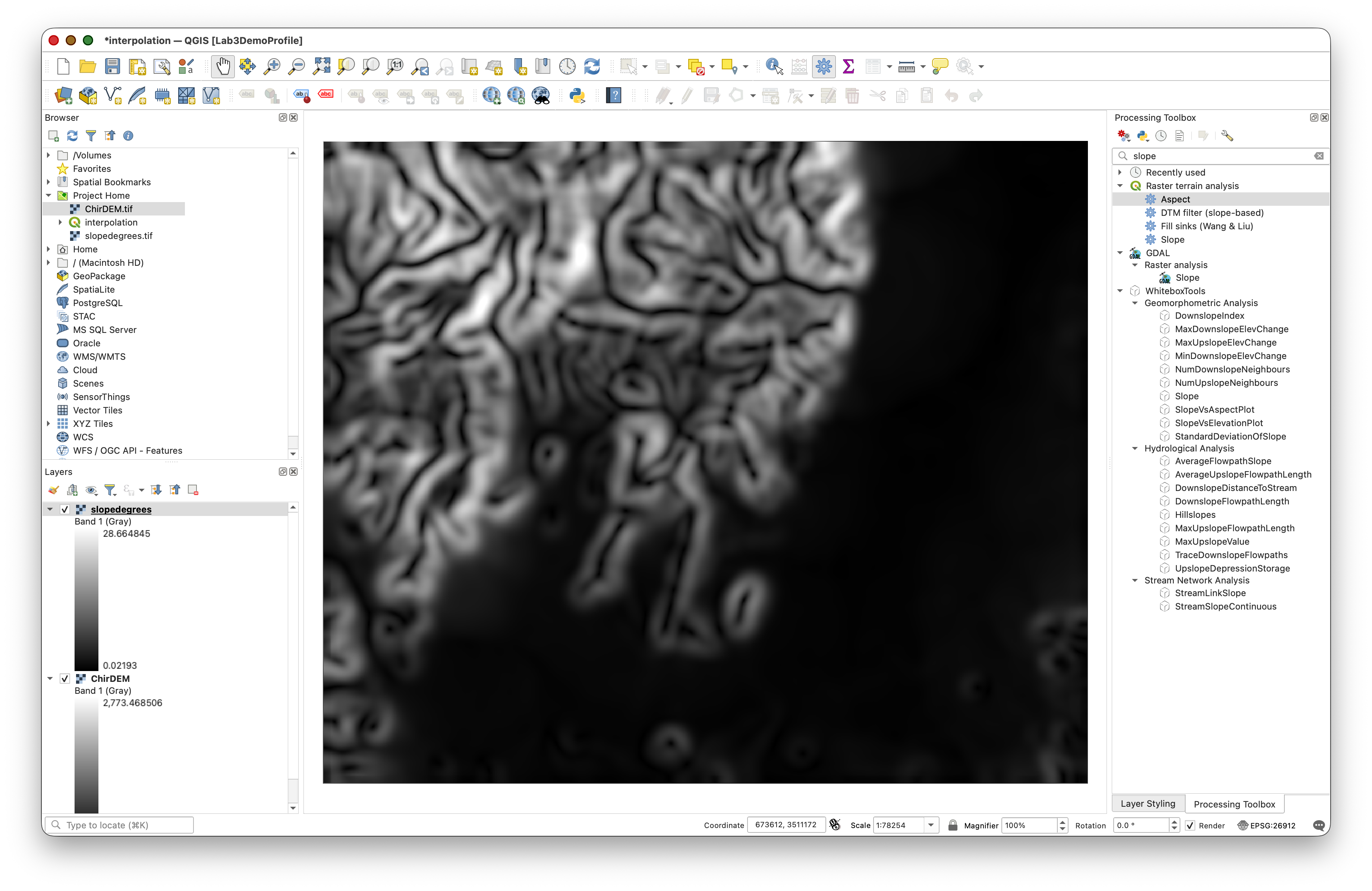
Concept note: Slope represents the rate of elevation change and is derived from the DEM. Steeper slopes indicate terrain where elevation changes rapidly over short distances. In this lab, slope becomes the criterion for stratification—we will sample more densely in steep areas.
Step 2: Reclassify Slope into Strata
Convert continuous slope values into three discrete classes representing flat, intermediate, and steep terrain.
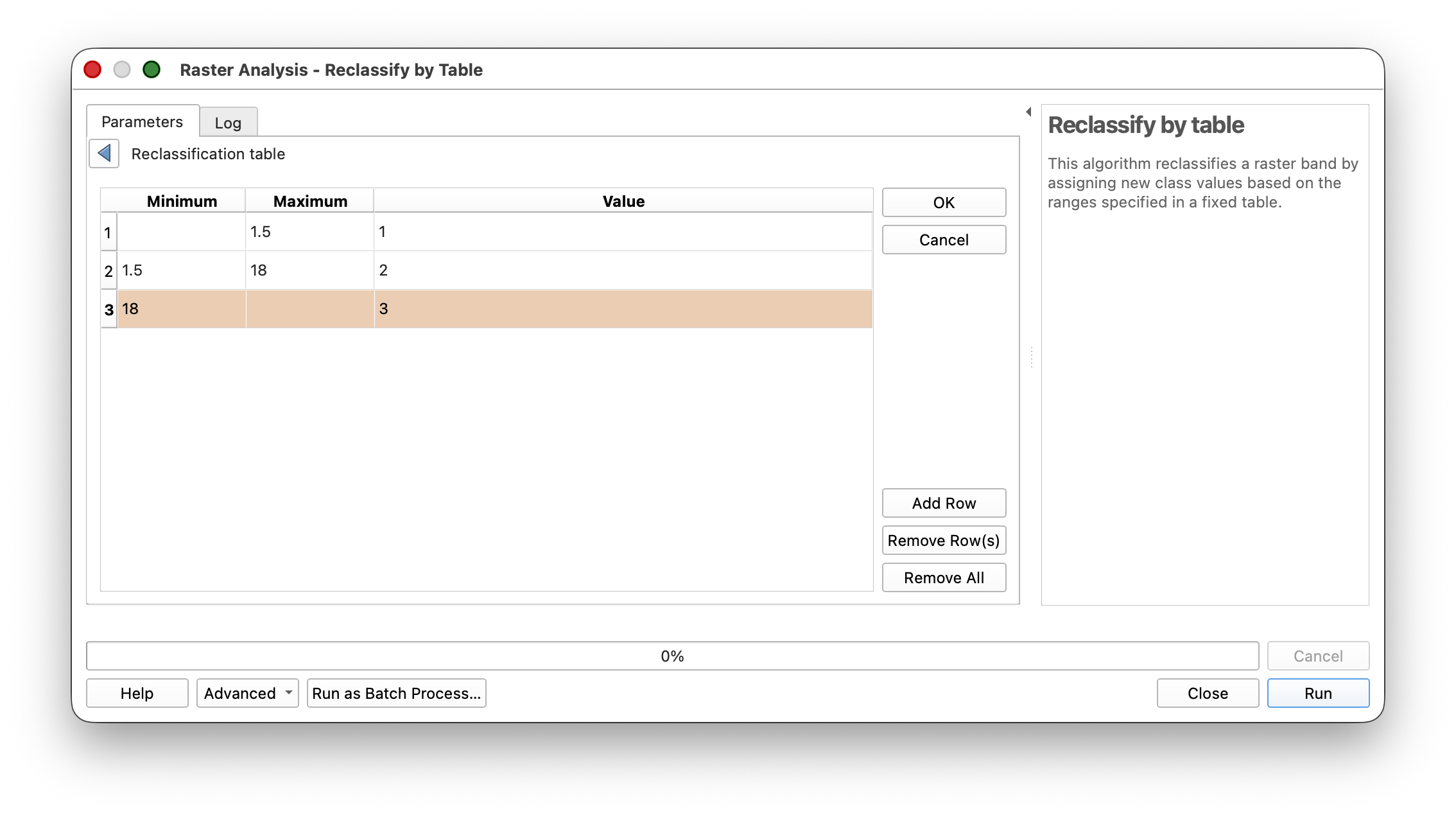
- Open Processing Toolbox > Raster > Analysis > Reclassify by table.
- Use the Slope Layer as your Input.**
- Click the ... button next to the Reclassification table to define your classes.
- Click Add Row to create
3rows. - Define three classes:
NoValue to 1.5(flat) as Class11.5 to 18(intermediate) as Class218 and NoValue(steep) as Class3
These thresholds were chosen to create reasonably balanced classes. In a real workflow, you would select thresholds based on domain knowledge—for example, slopes above which construction is infeasible, or elevations where a particular resource is unlikely to be found.
- Browse and save the output as ReclassSlope.
Your reclassified layer should look similar to this:
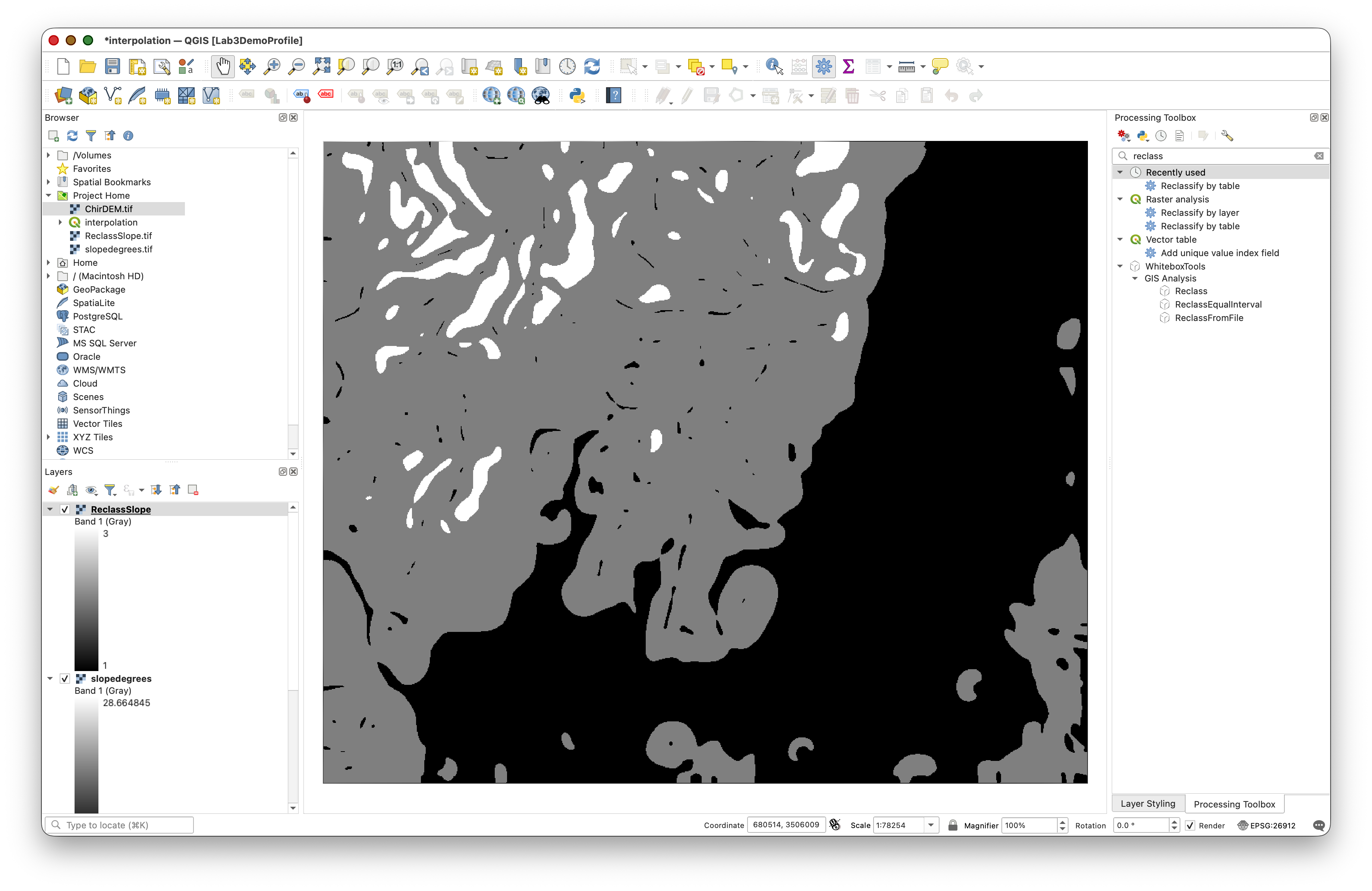
Workflow note: Reclassification reduces complexity by converting many continuous values into a small number of meaningful categories. This simplification is essential for stratification because it defines the population of each stratum.
Step 3: Apply Majority Filtering to Generalize Strata
Before creating sampling zones, generalize the reclassified slope to remove isolated single cells or long thin areas that would complicate stratified sampling.
- Open Processing Toolbox > Whitebox Tools > MajorityFilter.
- Specify:
- Input: ReclassSlope
- Filter X-Dimension: 10
- Browse and save the output as ReclassSlopeMajority
Toggle between the reclassified and majority-filtered layers to see how the filter removes small isolated zones:
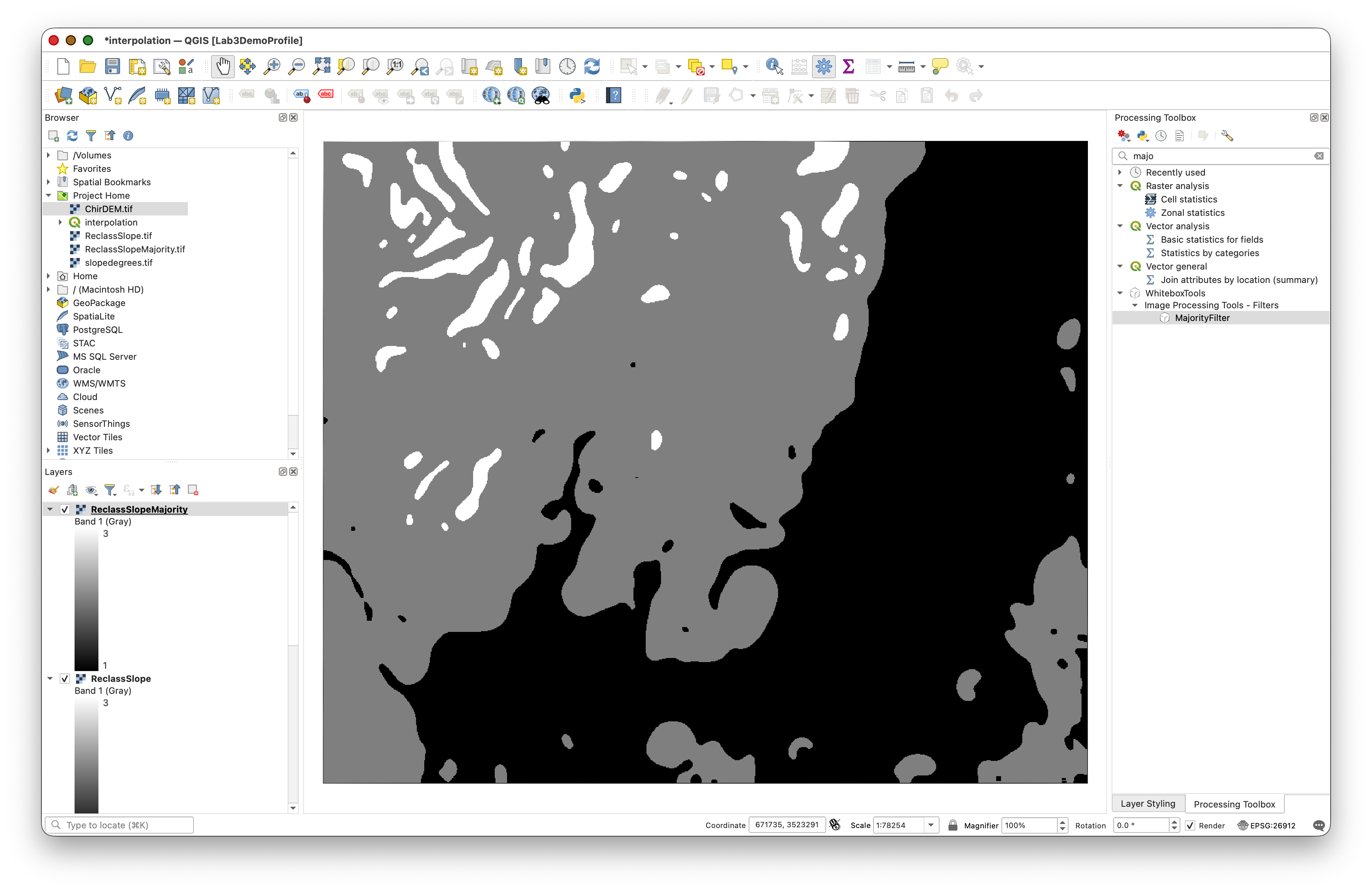
Concept note: A majority filter applies a local rule: for each raster cell, if more than half of the cells in a circular neighborhood belong to a particular class, assign that class to the center cell. This generalizes small, isolated patches and creates larger, more contiguous strata suitable for polygon-based sampling.
Step 4: Convert Raster Strata to Vector Polygons
Convert the generalized raster strata to a vector polygon layer that will define your sampling zones.
- Open Raster Conversion > Polygonize.
- Use ReclassSlopeMajority as input.
- Use the default settings.
- Browse and save the output vector polygons as STRATA.shp.
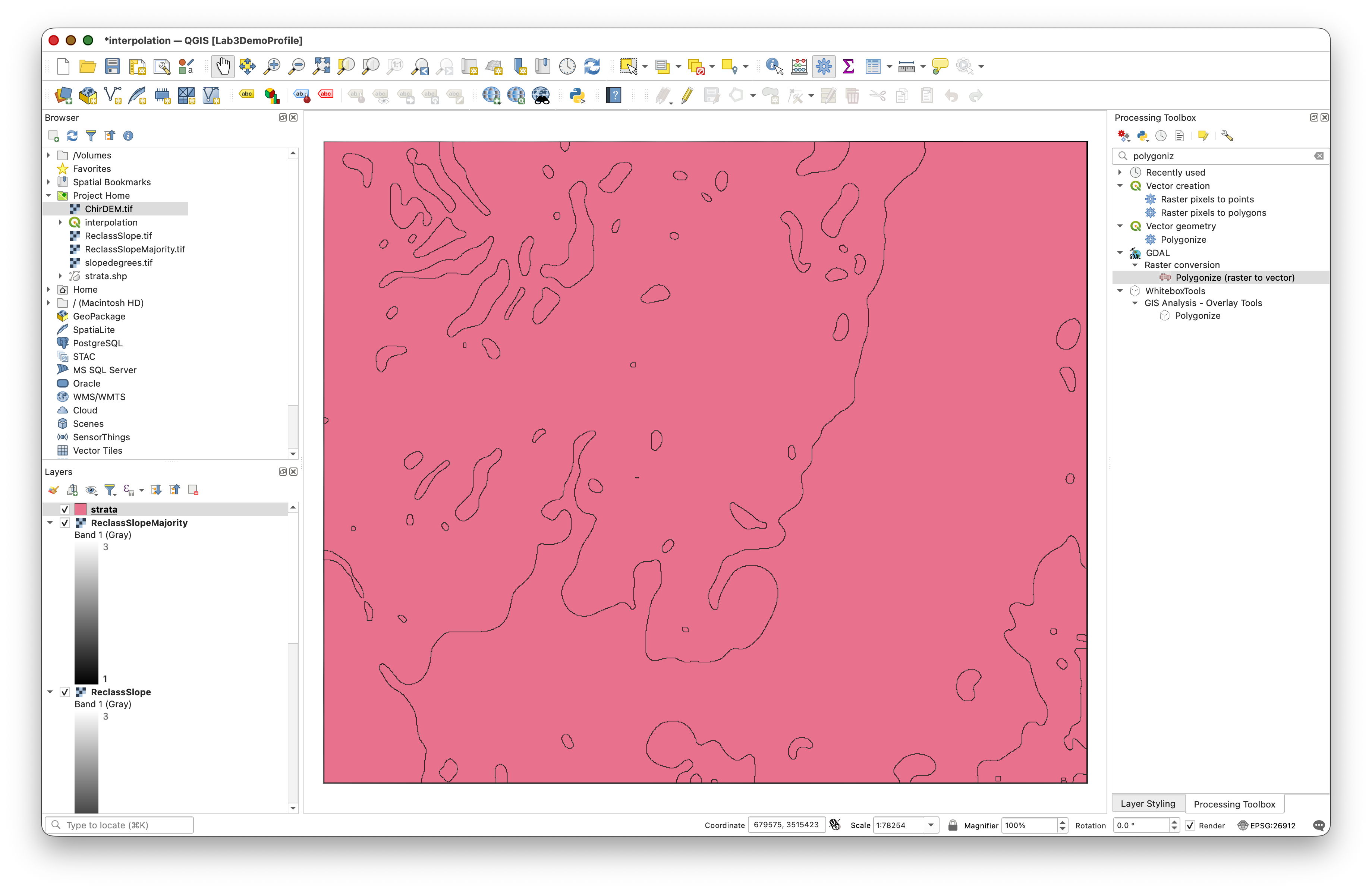
Step 5: Calculate Polygon Areas and Determine Samples per Polygon
Now you will use the area of each polygon to calculate how many sample points should fall within it, proportional to both its size and the desired sampling density for its stratum.
The sampling logic is:
- Flat areas (Class 1): 10% of 1000 = 100 points
- Intermediate areas (Class 2): 65% of 1000 = 650 points
- Steep areas (Class 3): 25% of 1000 = 250 points
These proportions reflect the assumption that steep areas warrant denser sampling to capture their complexity.
Calculating Individual Polygon Areas
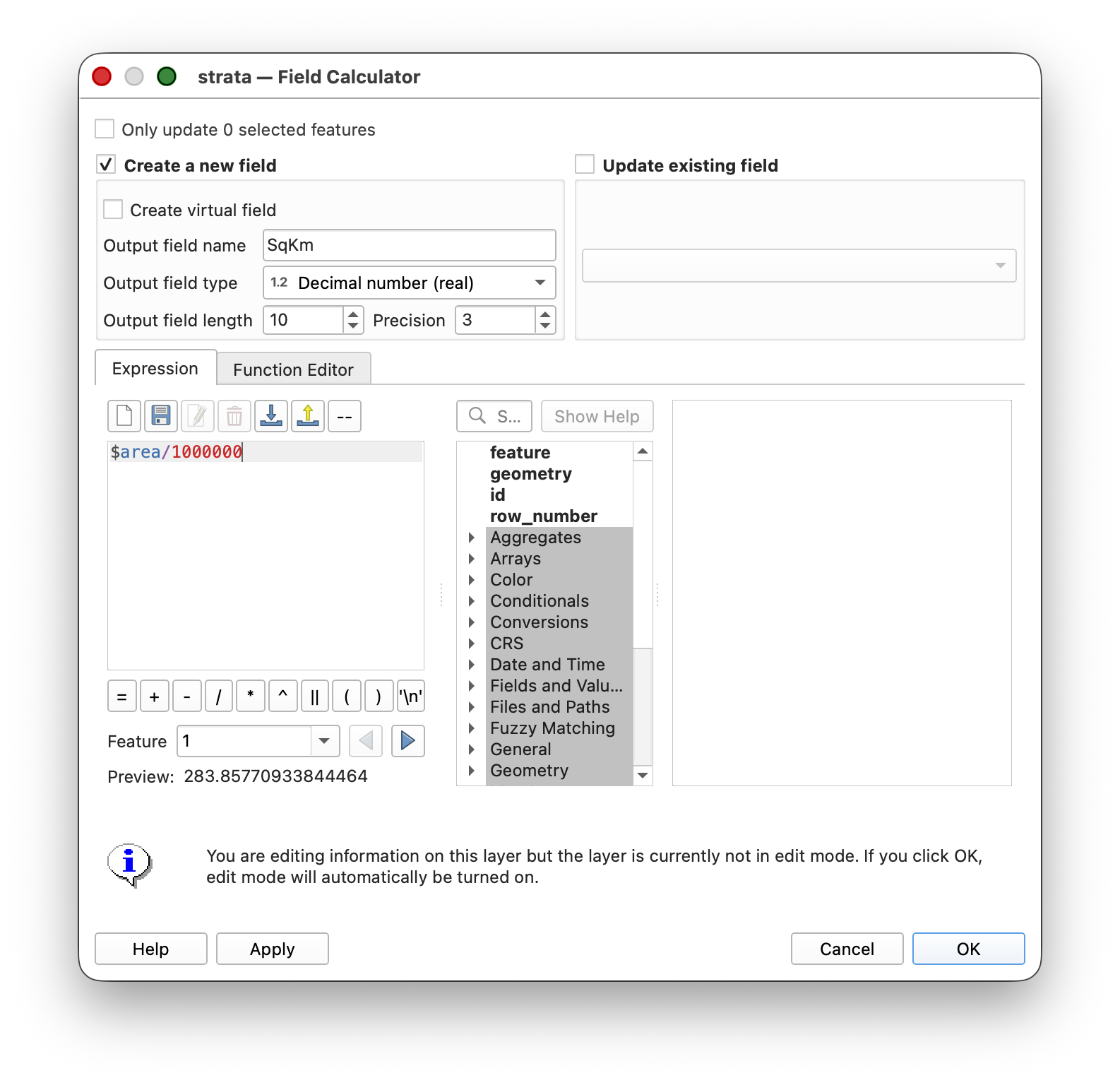
- Open the attribute table for the
STRATAlayer. - Toggle editing mode.
- Add a new field of type Decimal (Real) named
SqKm. - Use the Field Calculator to populate this field with polygon areas in square kilometers:
$area / 1000000
Computing Total Area per Stratum
You now need to find the total area for each class (flat, intermediate, steep) to use as a denominator in the sampling calculation.
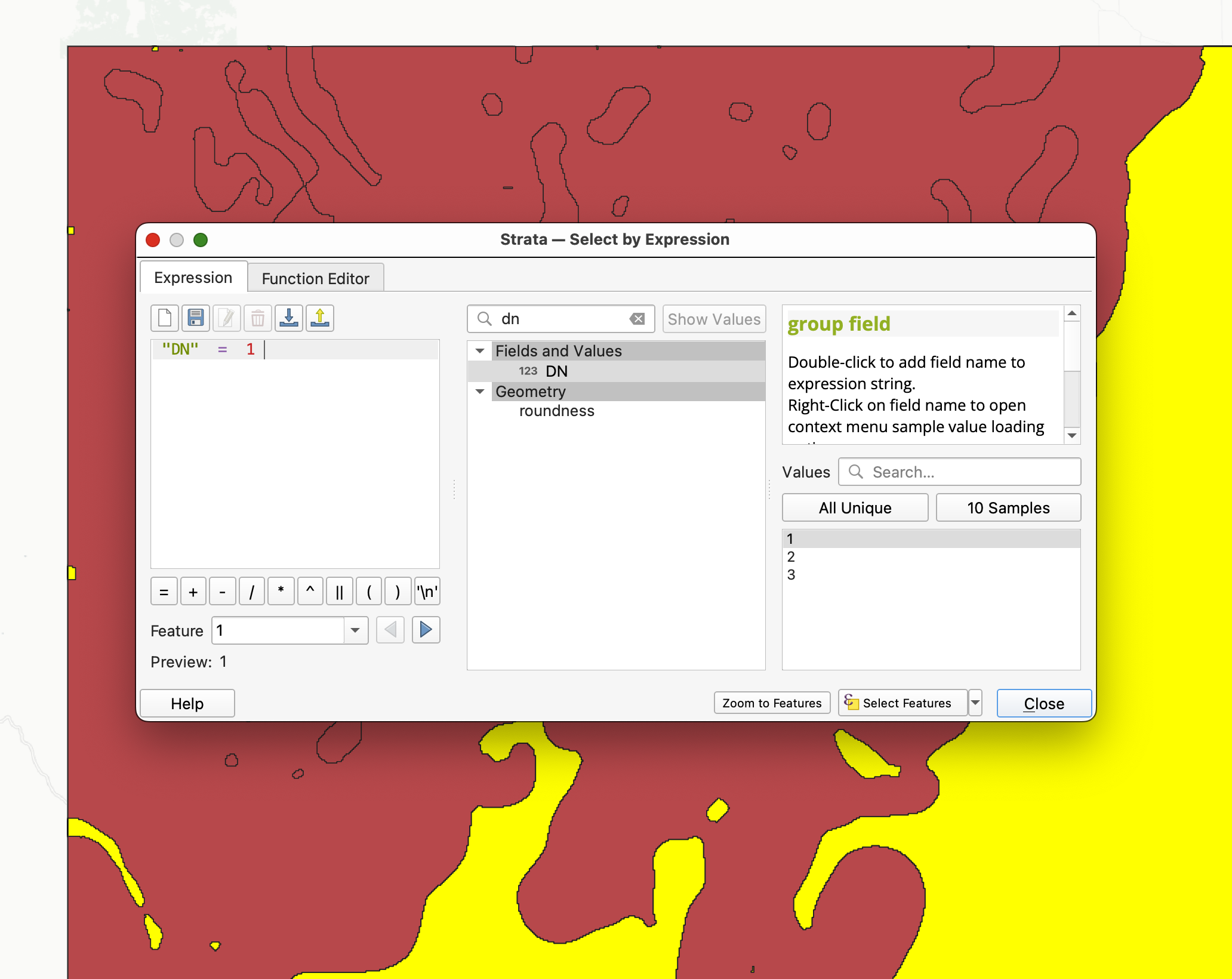
- Open the attribute table for the
STRATAlayer. - Select all polygons for one stratum class using Select features using an expression:
"DN" = 1
(Repeat for classes 2 and 3 separately.)
- Open Vector > Analysis > Basic Statistics for Fields.
- Check the box for Selected features only.
- Select the
SqKmfield and look at the SUM to get the total area for that class.
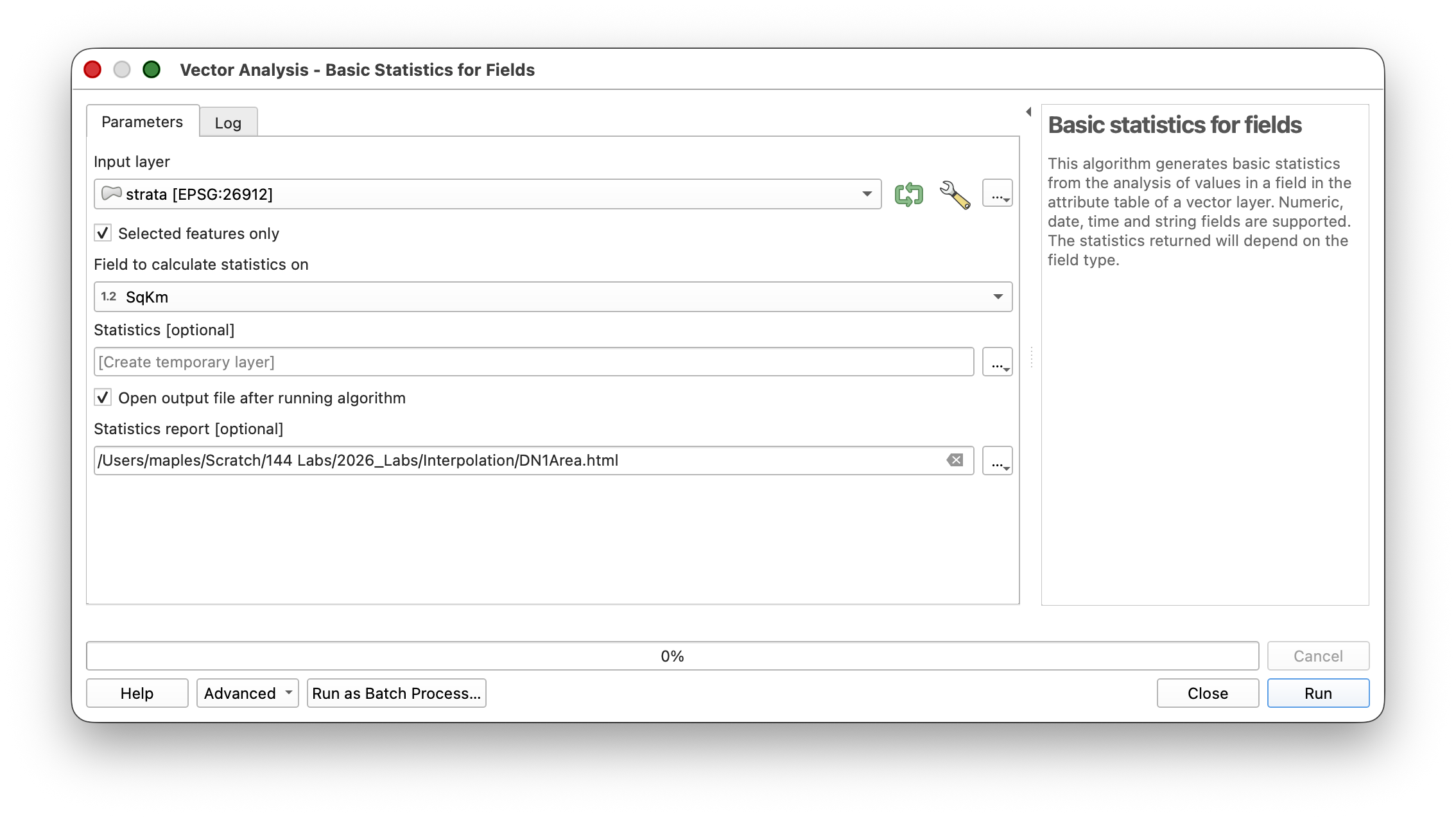
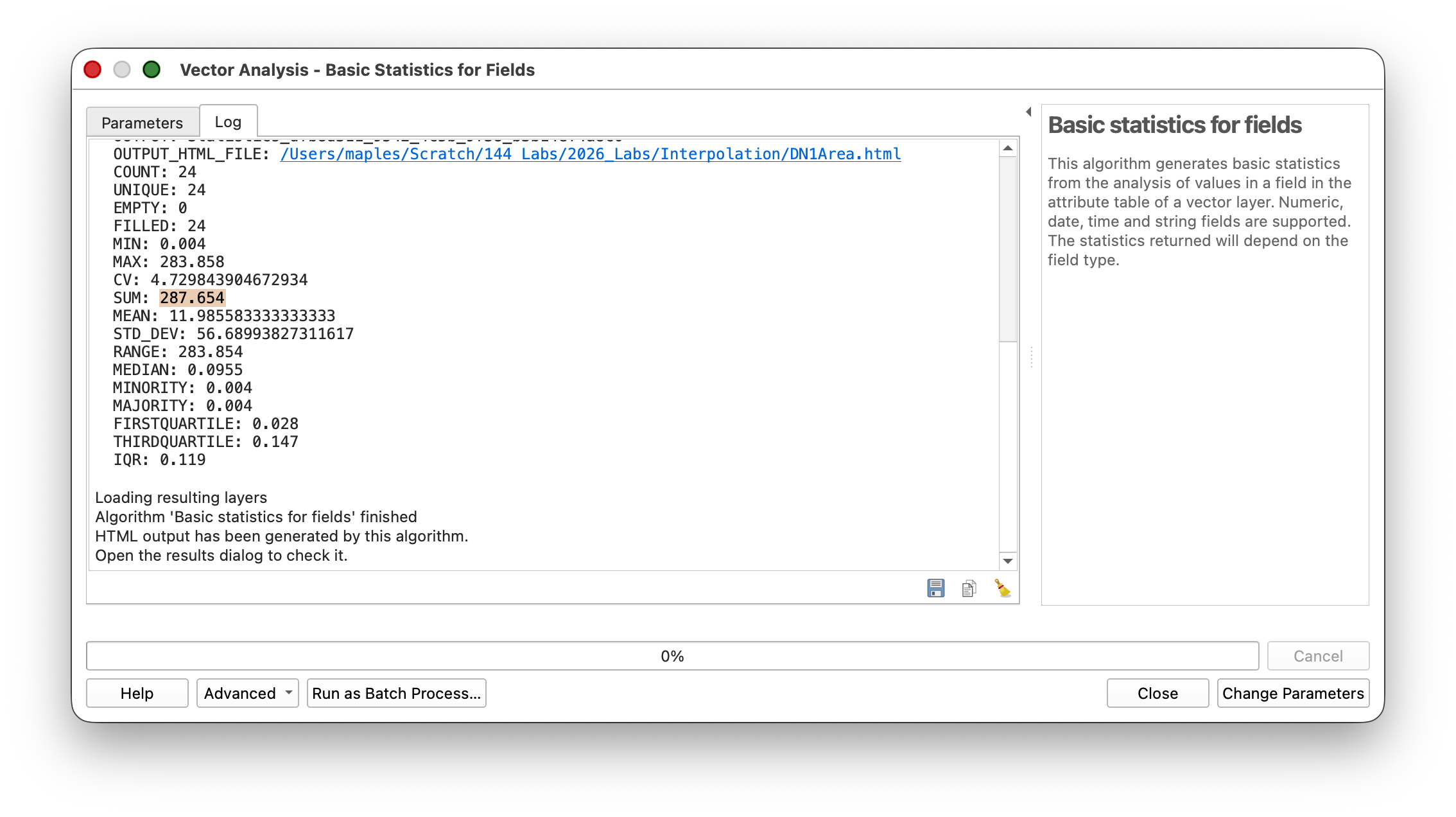
You should arrive at Area SUMs close to:
- Flat (DN = 1): approximately 287 square kilometers
- Intermediate (DN = 2): approximately 357 square kilometers
- Steep (DN = 3): approximately 25 square kilometers
(Your numbers may differ slightly depending on your earlier parameters.)
Workflow note: This approach uses feature selection to compute statistics on a subset. It lets you find the total area for each stratum without manually summing individual polygons.
Calculating Sample Count per Polygon
Now add a field that calculates how many sample points should be placed in each polygon based on its area relative to its stratum.
- Open the attribute table for the
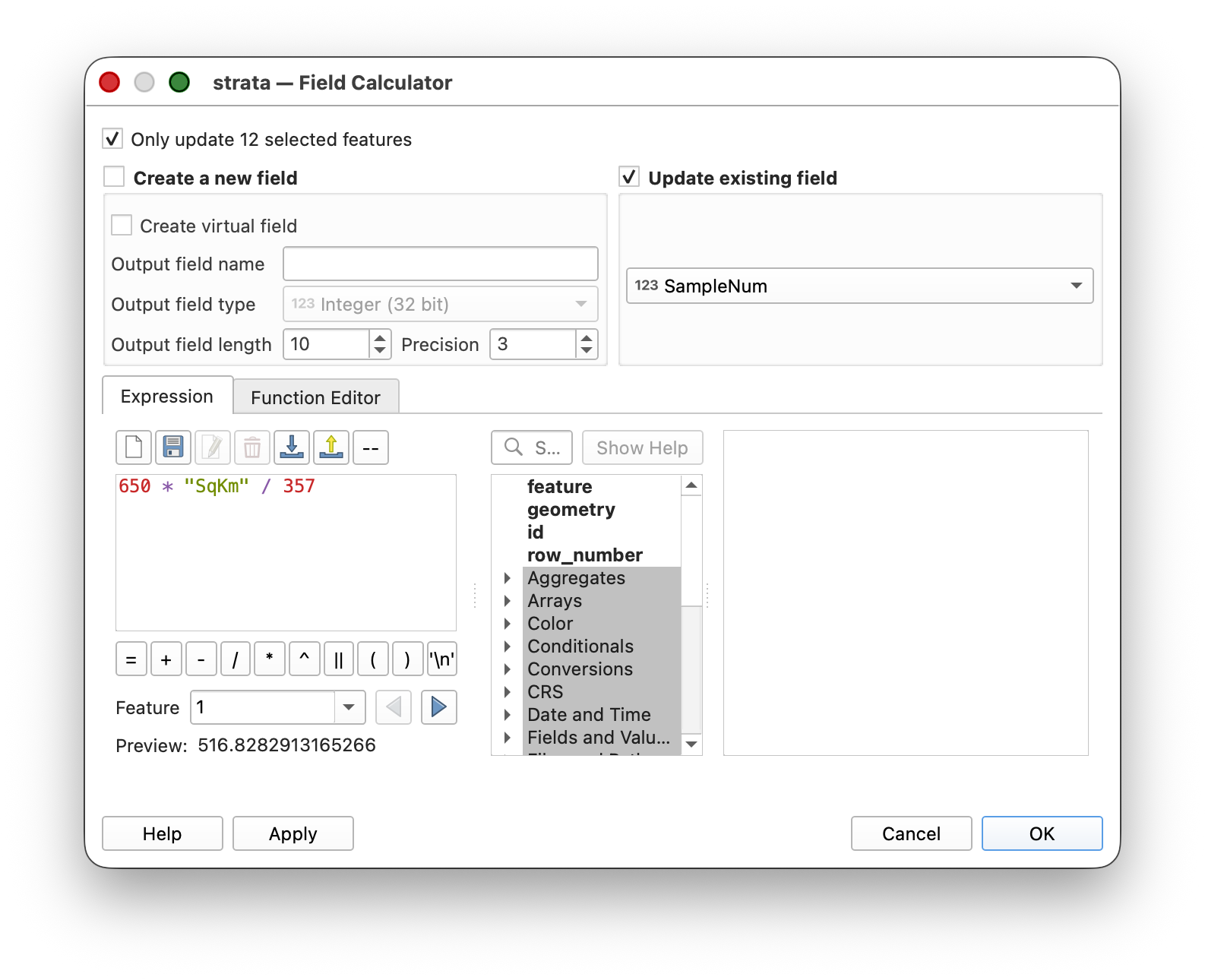
STRATAlayer and add a new Long integer field named samp_num. - Select all polygons for one stratum class, using Select features using an epression:
"DN"=1(Repeat for classes 2 and 3 seperately.) Use the Field Calculator to caluculate the number of samples for each polygon into a new field (for the first calculation, then use "Update") called
SampleNum. For each stratum, use a formula like:- DN = 1 (flat):
100 * "SqKm" / 287 - DN = 2 (intermediate):
650 * "SqKm" / 357 - DN = 3 (steep):
250 * "SqKm" / 25
- DN = 1 (flat):
- Calculate each formula separately for each class. After each calculation, select the next class and recalculate.
- Save your edits and toggle editing off.
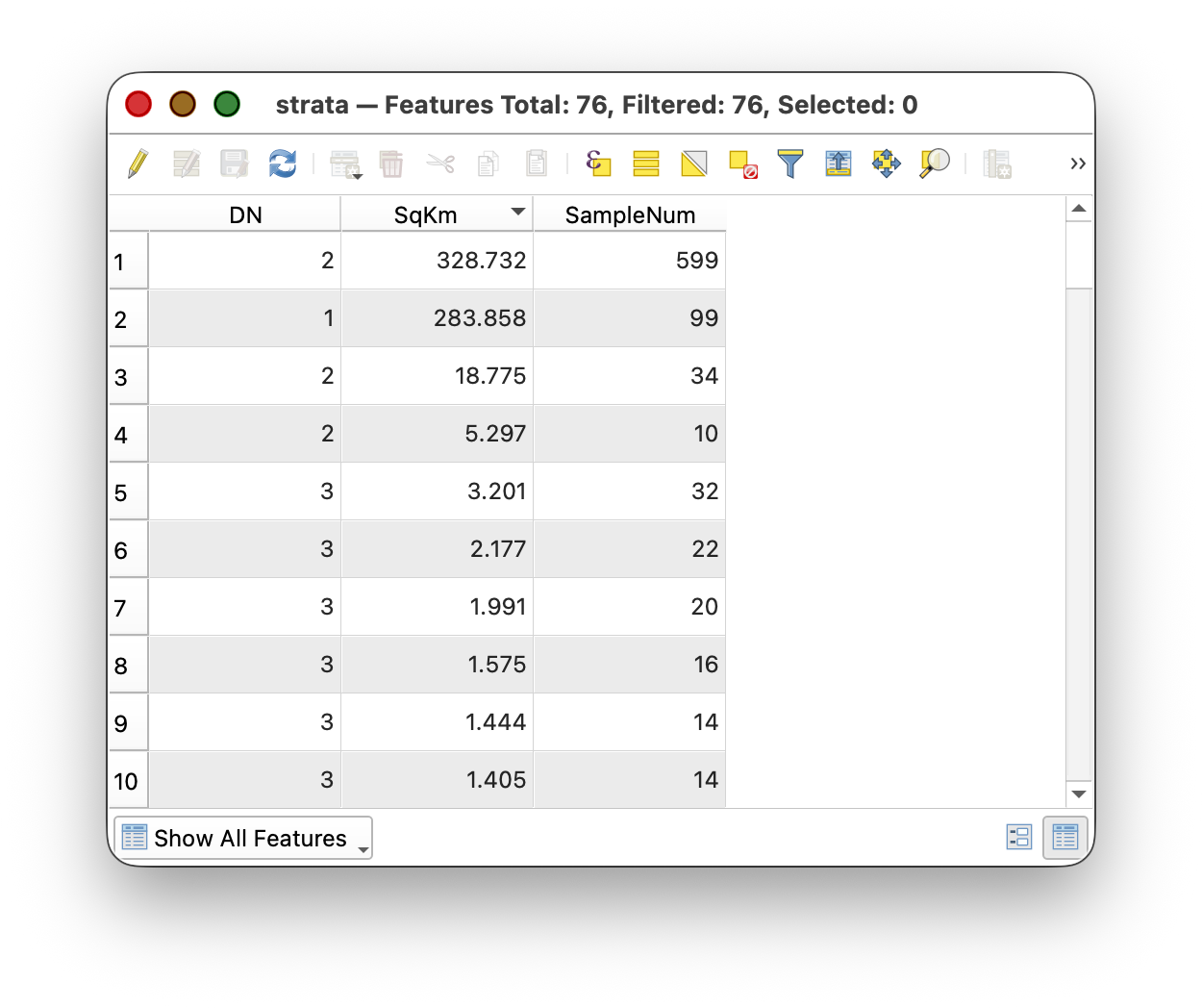
Concept note: This calculation distributes the target number of samples (100, 650, or 250 depending on class) proportionally across the polygons in each stratum based on their area. Larger polygons within a stratum get more samples; smaller ones get fewer, or none at all.
Step 6: Generate Stratified Random Points
Now create the stratified random sample using the samp_num field to determine point density within each polygon.
- Open Vector > Research Tools > Random Points in Polygons.
- Set Input polygon layer to
STRATA. - For the Number of points for each feature option, click the button on the right end of the field.
- From the dropdown, select Field type > samp_num to use the field you just calculated.
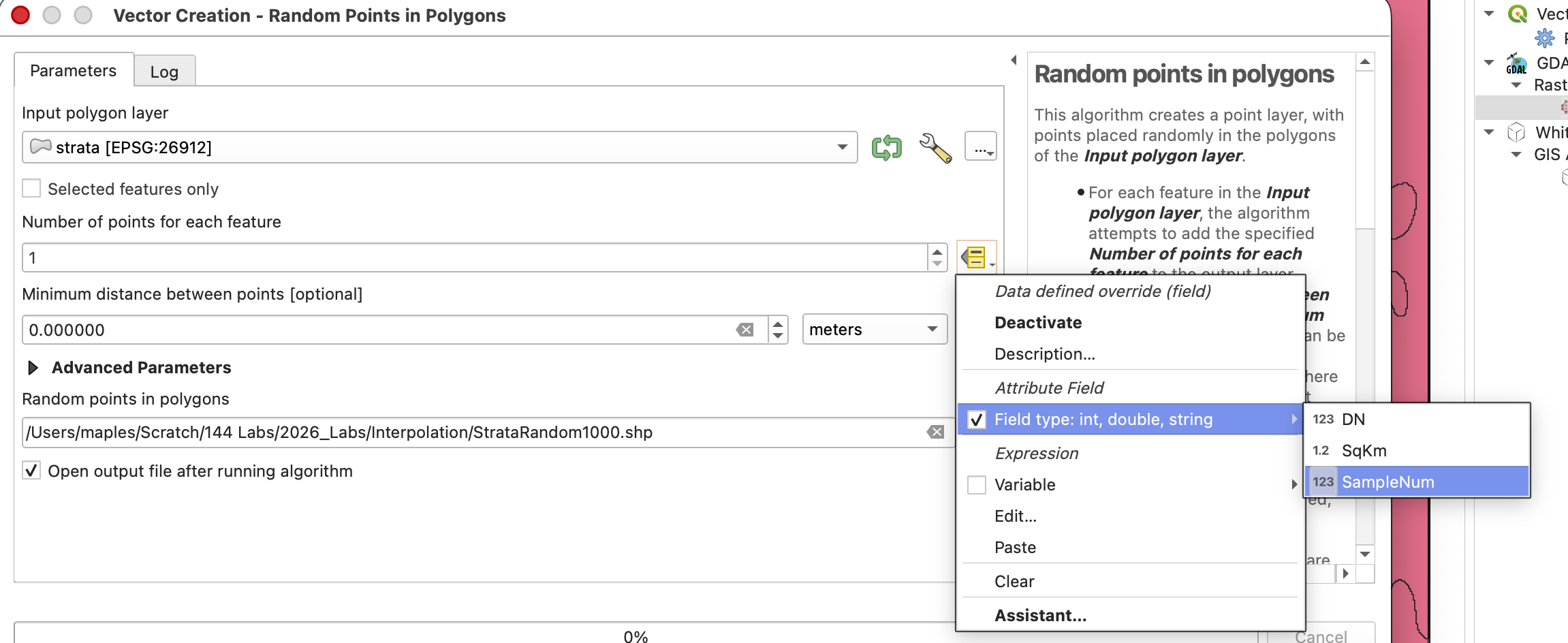
- Browse and save the Output random points in polygons as StrataRandom1000.shp
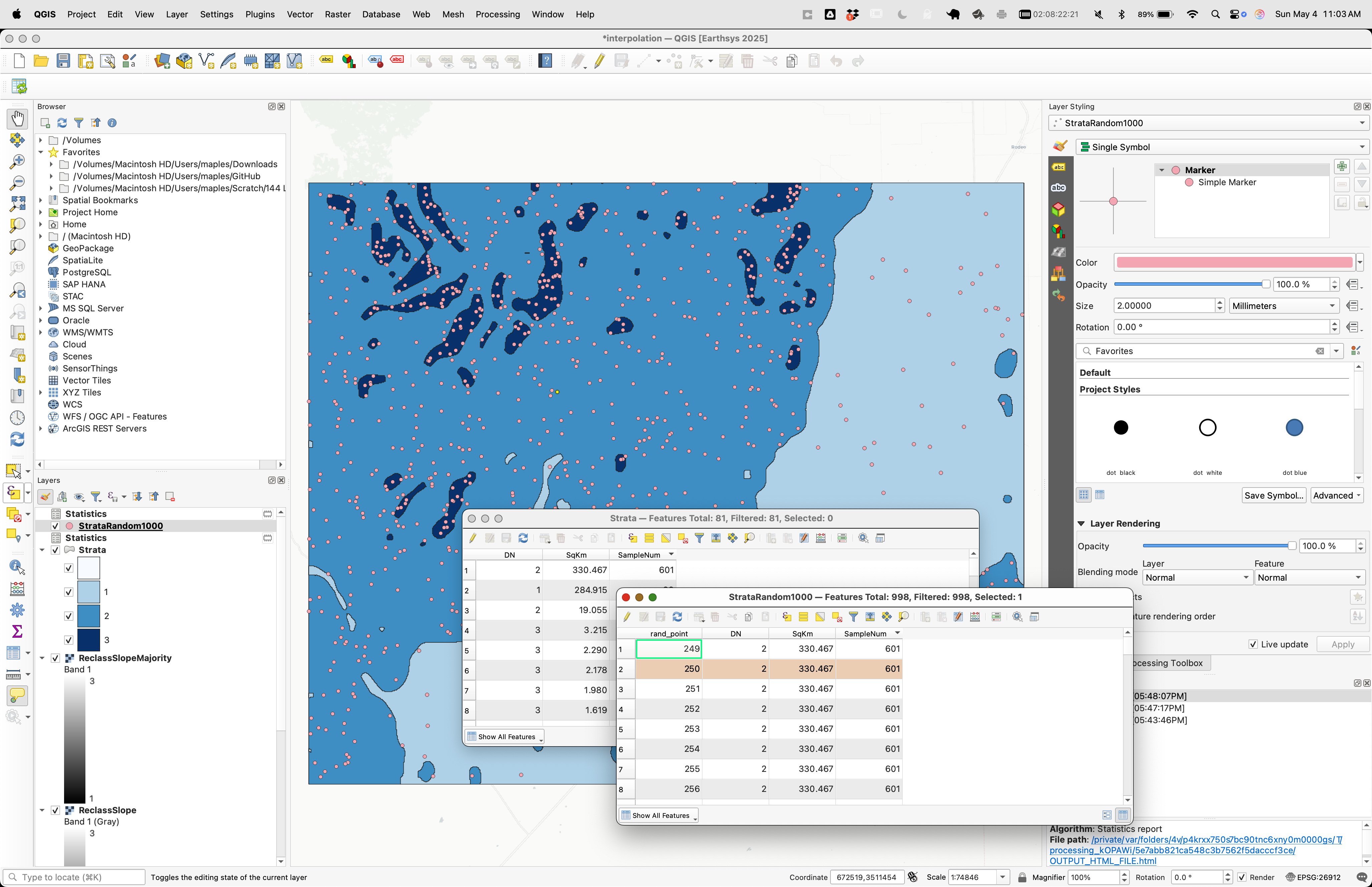
This generates a point layer with higher sampling density in the steeper areas (where samp_num is larger) and lower density in flatter areas:
Workflow note: To add colors to your map, change the
STRATAlayer's symbology to Categorized using DN as the value field. This helps visualize which strata are being sampled more densely.
Step 7: Extract Elevation Values from Stratified Samples
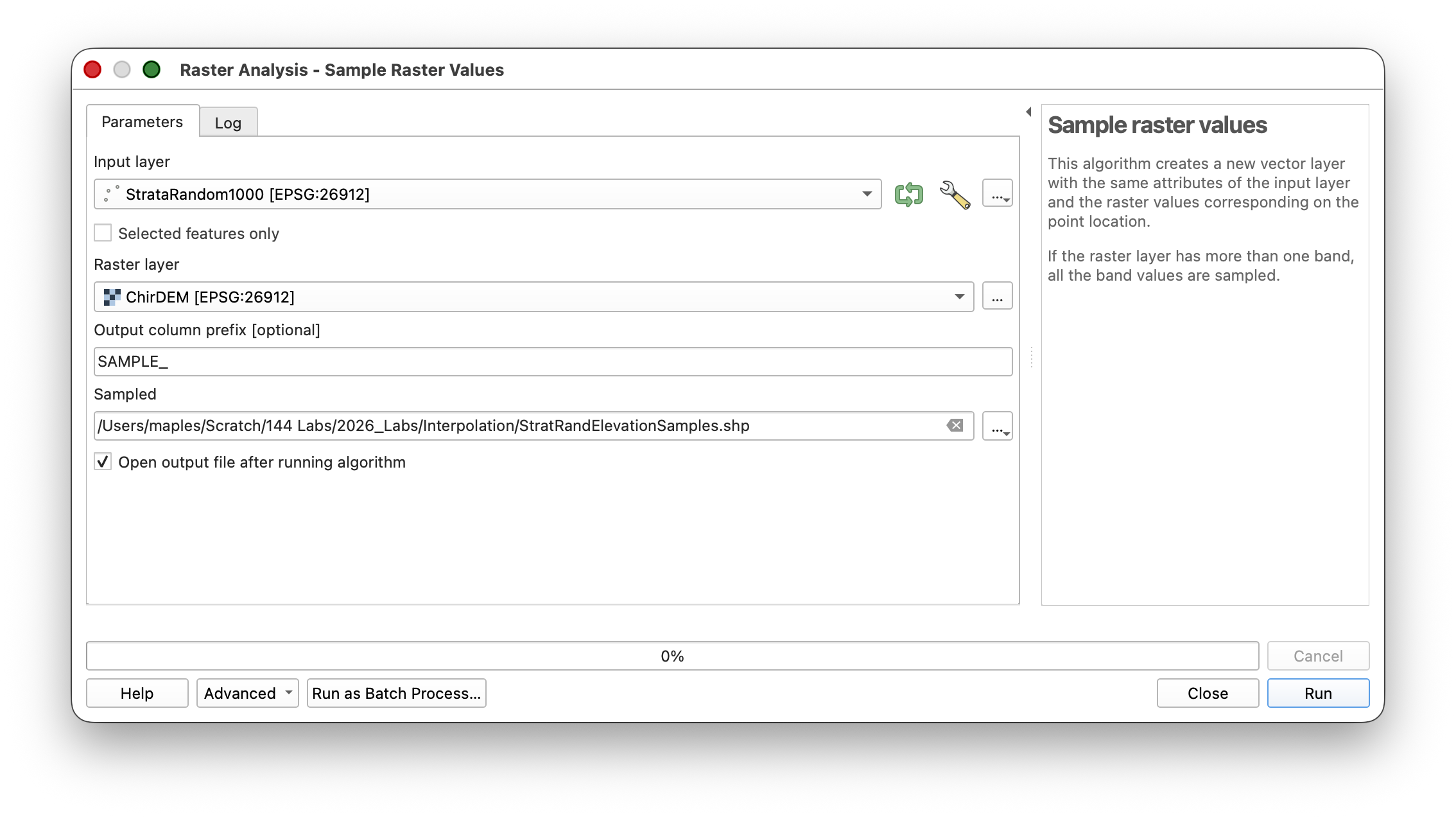
As before, sample the elevation values from the DEM at these stratified random points:
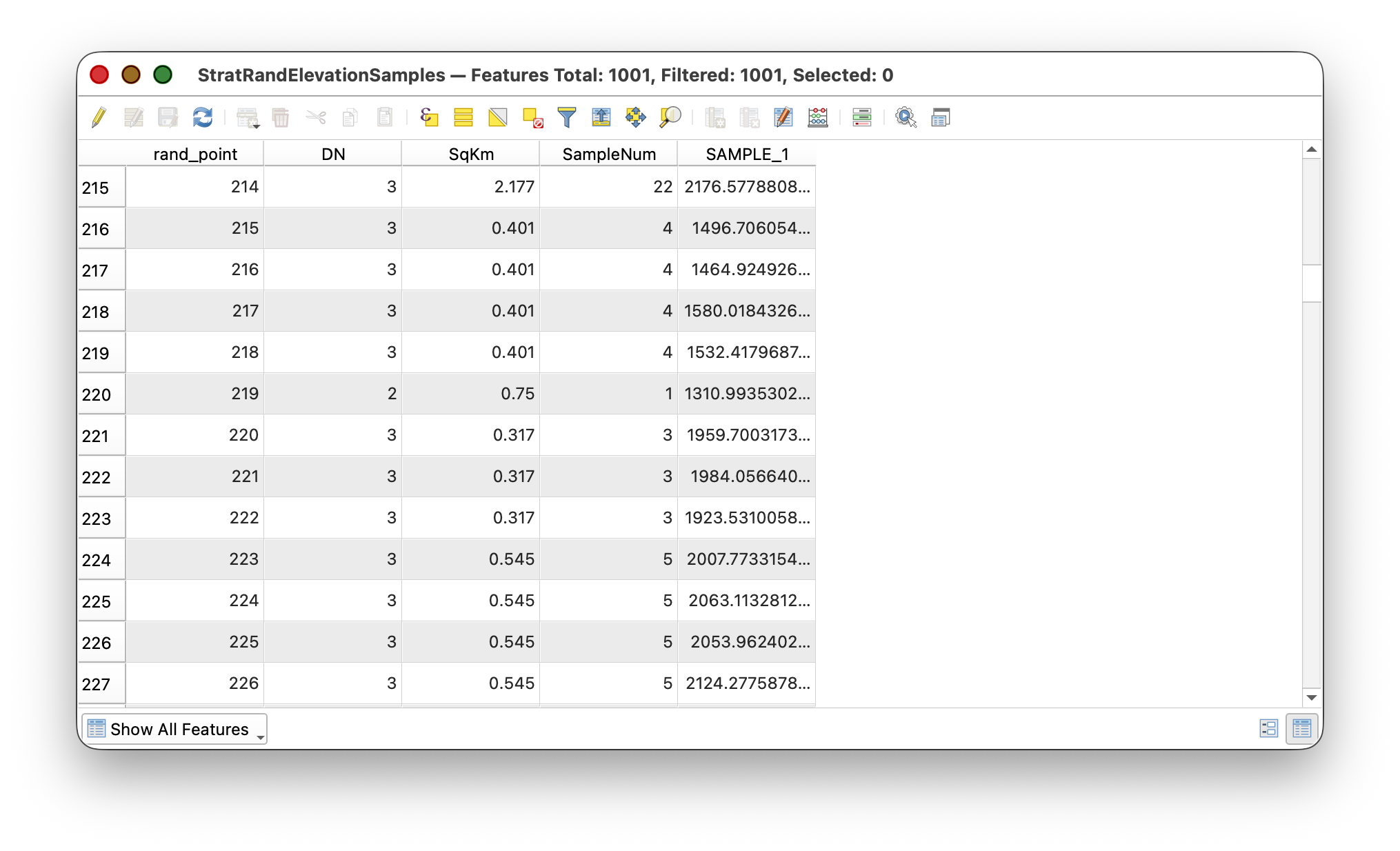
Step 8: Radial Basis Function (RBF) Interpolation
RBF interpolation creates a smooth continuous surface that minimizes overall curvature. Like other smooth interpolation methods, it favors smooth transitions rather than sharp breaks. The main difference for this updated lab is that you should use the Whitebox RBF tool instead of the discontinued SAGA Multi-level B-spline tool.
- Open Processing Toolbox > Whitebox Tools > Radial Basis Function Interpolation (or search for RBF Interpolation).
- Specify:
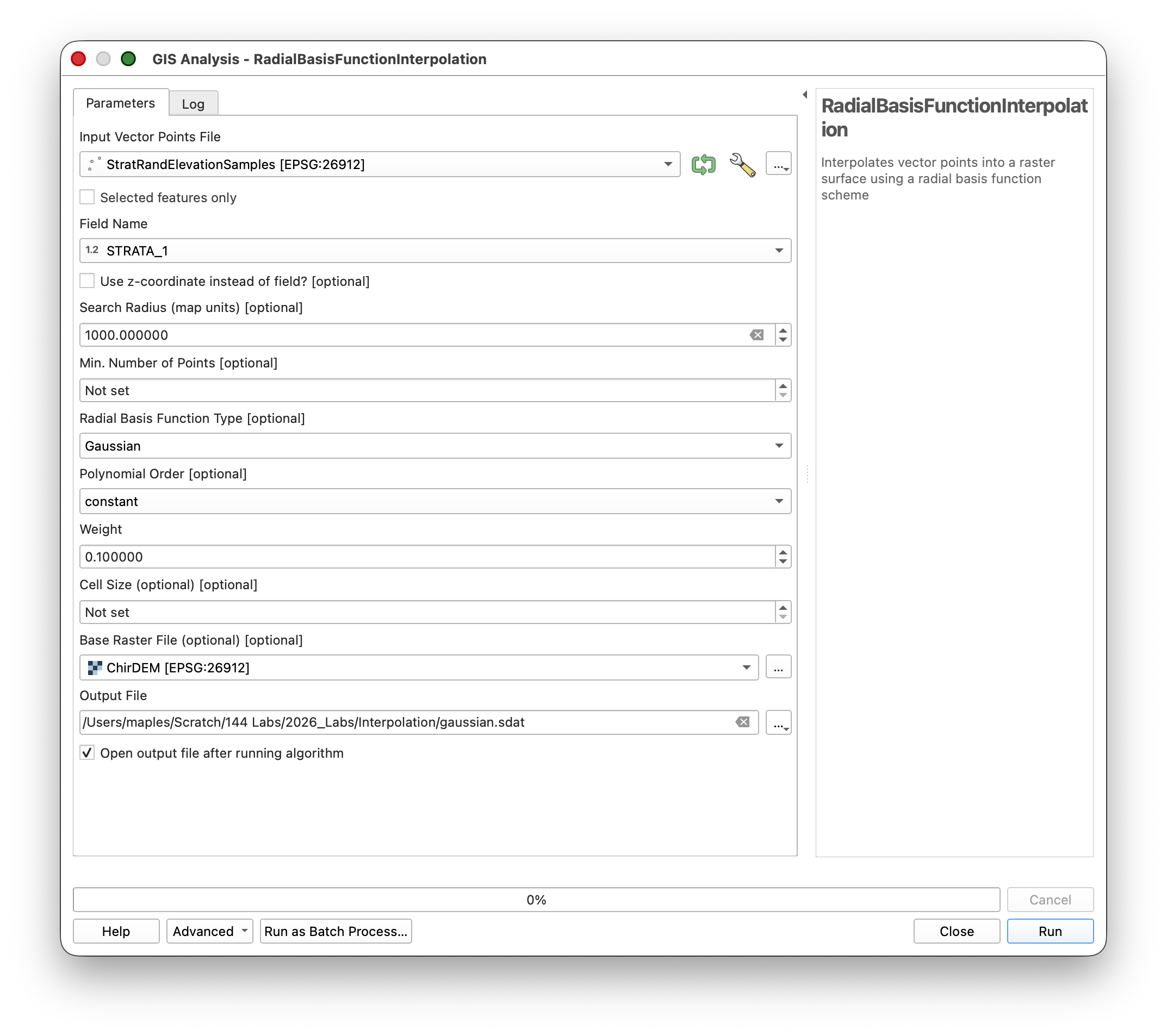
- Run the tool.
Concept note: RBF interpolation fits a smooth function through the sample points by minimizing curvature. It does not necessarily pass exactly through every sample point, but it produces a continuous, smooth surface without the sharp discontinuities of Nearest Neighbor or the localized patterns of IDW.
Step 9: Finishing the RBF Layer
Now complete the RBF surface by adding supporting layers and organizing them:
- Calculate contours from the
RBFStratRandsurface using Raster > Extraction > Contour with an interval of100meters. - Create an
RBFHillshadelayer using Raster > Terrain Analysis > Hillshade with Azimuth 315 and Elevation 25. - Copy the color style from your original
ChirDEMlayer and paste it onto theRBFStratRandlayer. - Group the RBF layers (
RBFStratRand,RBFHillshade, and contours) in the Layers panel under a group named RBF Stratified.
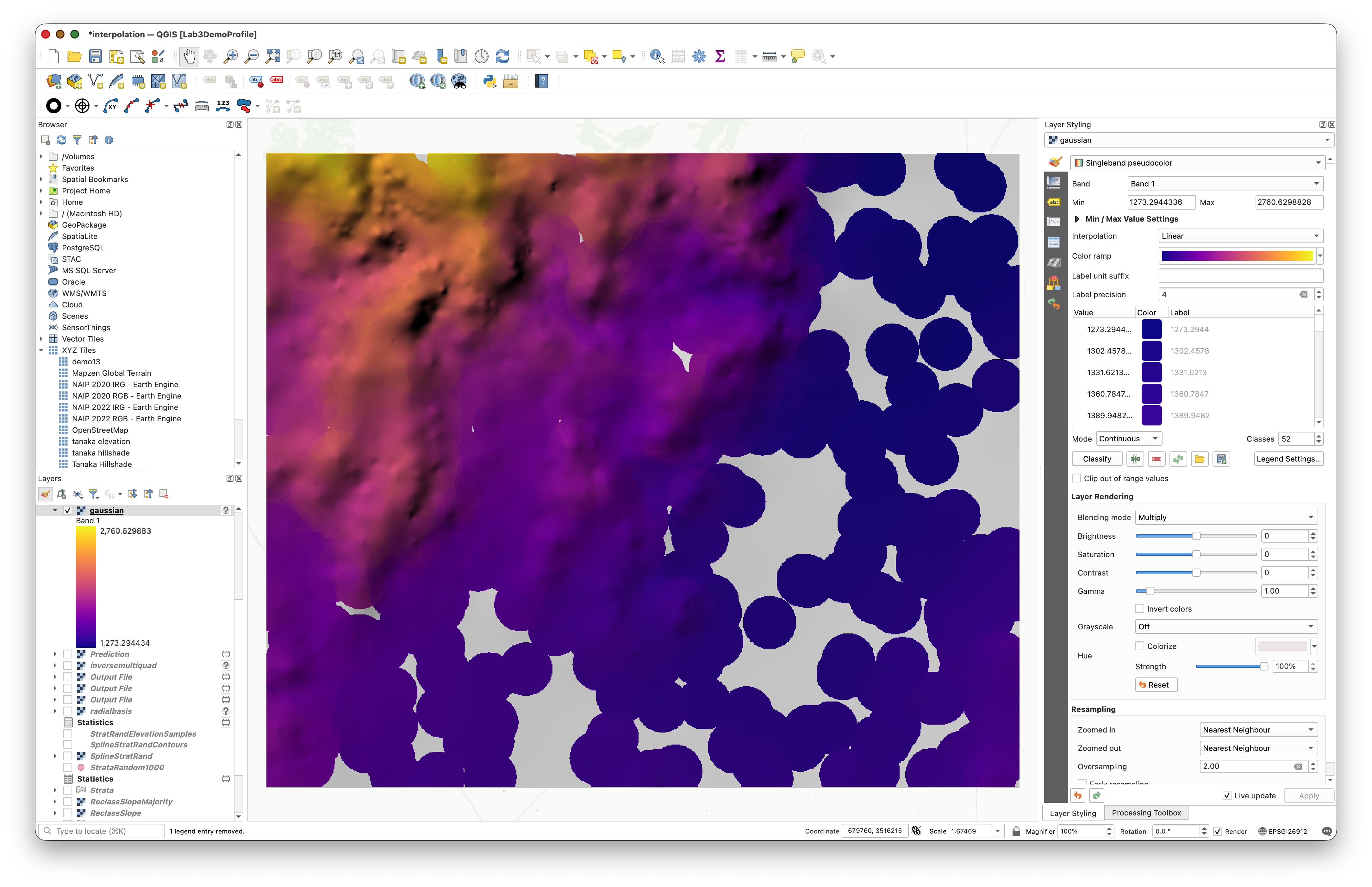
Final Deliverable: Comparison Map Layout
You now have four complete interpolation results:
- Original (the source DEM)
- Inverse Distance (systematic sampling + IDW interpolation)
- Nearest Neighbor (random sampling + Nearest Neighbor interpolation)
- RBF Stratified (stratified random sampling + Radial Basis Function interpolation)
Create a final map layout that displays all four methods side by side for visual comparison.
Concept note: Comparing interpolation methods visually helps you understand their characteristics. IDW shows radial patterns around sample points. Nearest Neighbor produces discrete zones. RBF creates smooth transitions. Stratified sampling focuses effort where variation is greatest. No single method is universally best—choice depends on your data, sample density, and application.
Layout Instructions
- Set your print canvas to landscape orientation.
- Create four map frames arranged side by side, one for each group (Original, Inverse Distance, Nearest Neighbor, RBF Stratified).
- For each frame:
- Locked (check the Lock Item box in Item Properties so you don't accidentally move it while working on others)
- Locked layers (check the Lock Layers option in Layer Properties)
- Arrange the layers within each frame consistently using this order from bottom to top:

Styling Tips
You can easily copy and apply consistent styling across methods:
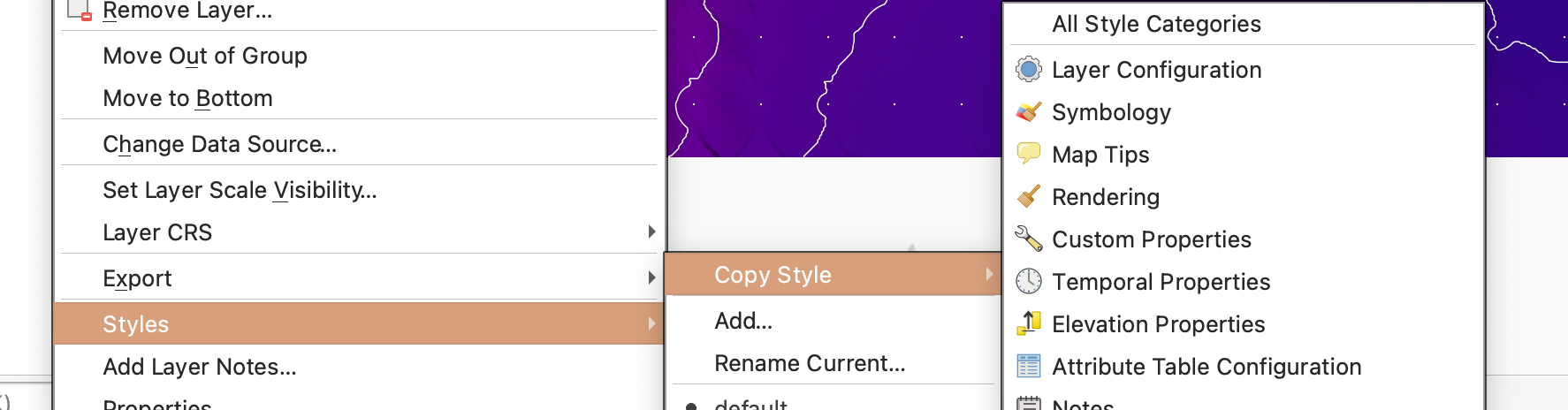
- Right-click on a layer you want to copy the style from.
- Select Styles > Copy Style > All Style Categories.
- Right-click on the layer you want to style and select Styles > Paste Style > All Style Categories.
This ensures that all four maps use the same color ramp and classification for the elevation surface, making them directly comparable:
Map Document Requirements
Include on your final map layout:
- Clear titles for each of the four map frames identifying the sampling method and interpolation technique
- A scale bar
- A north arrow
- Your name and the lab submission date
- A brief legend explaining the color ramp and any other symbology used
Export and submit your layout as a PDF.
Workflow note: Locking items and layers prevents accidental changes as you refine the layout. This is especially important when working with multiple map frames.